
IDL、代码生成与跨语言RPC:以protobuf + gRPC为例
你有没有想过这样一件事:一个用Go写的客户端,发送一段数据到用C++写的服务端,对面收到的字段名、字段类型、字段语义居然能完全对得上?再进一步,几十个团队、几十种语言、几百个微服务彼此调来调去,怎么保证大家对”同一个接口”理解一致、不会因为某一方加了字段而把别人搞挂? 这背后是一整套支撑”跨语言通信”的工程机制。这篇文章先把这套机制抽象出来——它由”契约+代码生成+统一二进制规范”三件事构成;然后以protobuf + gRPC这一组合为例把每一块具体看一遍:protobuf负责契约和字节,gRPC负责把字节真正送过网络,二者一起构成当前最广泛使用、生态也最完整的一种实现。 跨语言通信的...
从一个oneof争论说起:protobuf的序列化原理与设计哲学
最近在和同事讨论一个内部RPC服务的协议设计,争论的焦点是一个看起来略有冗余的oneof类型。我当时有两个朴素的直觉判断:一是oneof里几个相近的容器case看起来可以合并掉一些,没必要写得这么细;二是oneof里塞这么多case,线上传输的字节开销大概会随case数线性上升。把这两件事想清楚的过程让我重新整理了一遍protobuf的设计逻辑:从wire format的字节布局,到数据结构层面的取舍。事后回头看,这两个直觉判断都不准确——这篇文章就从那个争论出发,沿着这条主线把protobuf的几层机制讲一遍,同时回答一个更大的问题:这套看起来颇为复杂的协议体系,为何成为大型分布式系统...

面向长时运行应用开发的 Harness 设计
2023、2024 年,大家在学怎么「问」模型——Chain-of-Thought、Few-Shot、角色扮演,核心是把一句话说得让 AI 听懂,这是 Prompt Engineering 的时代。2025 年,Andrej Karpathy 一句话点醒了很多人:光会写 prompt 不够,你得设计模型「看到什么」。RAG、MCP、Memory、工具调用……重点是把整个 context 窗口当成系统来设计,这是 Context Engineering 的时代。 到了 2026 年,问题又往前推了一步:模型已经足够强,context 也设计得够好,但要让它在无人干预的情况下独立跑几个小时、...
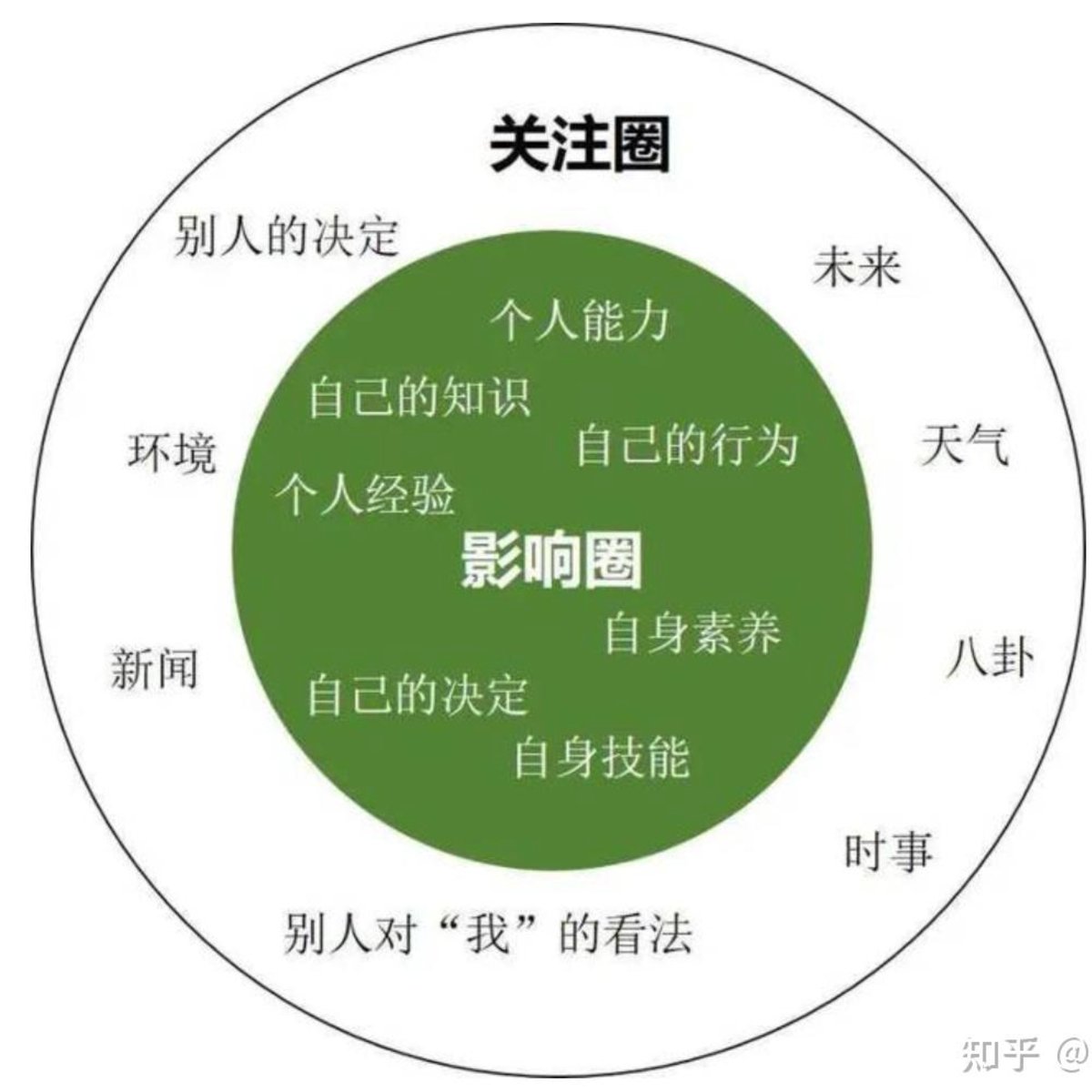
信息越多,越需要过滤与专注
移动互联网之前,是人找信息,你想知道什么才去找什么。后来逐渐变成信息找人,再后来干脆是信息淹没人。在这种情况下,最重要的已经不是怎么接收信息,而是怎么过滤信息。 面对任何信息,学会默认不接收,除非确实有必要。如果一篇文章的标题在强烈引诱你,那就不要点开。如果一个视频的前三秒是在试图让你看下去,那就不要看下去。朋友圈刷到一条让你心里一紧的消息,不一定要点进去看。群里转来的链接,不一定要打开。播客推送了一期听起来很有意思的节目,不一定要加进待听列表。设计来抓住你注意力的东西,目的是抓住你的注意力,不一定是给你什么有用的东西。宁可错杀一千,不可放过一个——真正重要的消息,总会通过各种渠道涌到你...

高级语言的分类方式
高级语言自诞生以来已发展出数百种之多,它们在语法、执行方式、类型系统和设计哲学上各有特点。为了理解这些语言之间的异同,我们可以从多个维度对其进行分类。这些分类维度并非互斥——一门语言往往同时属于多个类别,例如 Python 是解释型、动态类型、强类型的多范式语言。理解这些分类方式,有助于在面对具体问题时选择合适的工具。 按执行方式程序从源代码到被计算机执行,需要经历翻译过程。按翻译方式的不同,语言可分为编译型和解释型两大类。 编译型编译型语言在程序运行前,由编译器将源代码整体翻译为目标平台的机器码(或中间码),生成可执行文件后再运行。这一过程使得编译型语言在运行时无需额外的翻译开销,通常...

C++移动语义
C++11引入的移动语义是一项重大的性能优化,它允许”窃取”临时对象的资源而非复制,从根本上消除了大量不必要的深拷贝开销。理解移动语义,需要先弄清楚C++如何区分”可以移动”和”不可移动”的对象——这就是值类别体系;然后理解如何在语法层面捕获这种区分——这就是右值引用;最后才是移动操作的具体实现和应用场景。 值类别C++中的每个表达式都有两个独立的属性:类型(type)和值类别(value category)。类型描述表达式的数据结构,值类别则描述表达式的身份和可移动性。 C++11将值类别分为三个基本类别: lvalue(左值)是有持久身份的表达式,可以取地址,例如变量名、解引用表达...