C++移动语义
C++11引入的移动语义是一项重大的性能优化,它允许”窃取”临时对象的资源而非复制,从根本上消除了大量不必要的深拷贝开销。理解移动语义,需要先弄清楚C++如何区分”可以移动”和”不可移动”的对象——这就是值类别体系;然后理解如何在语法层面捕获这种区分——这就是右值引用;最后才是移动操作的具体实现和应用场景。
值类别
C++中的每个表达式都有两个独立的属性:类型(type)和值类别(value category)。类型描述表达式的数据结构,值类别则描述表达式的身份和可移动性。
C++11将值类别分为三个基本类别:
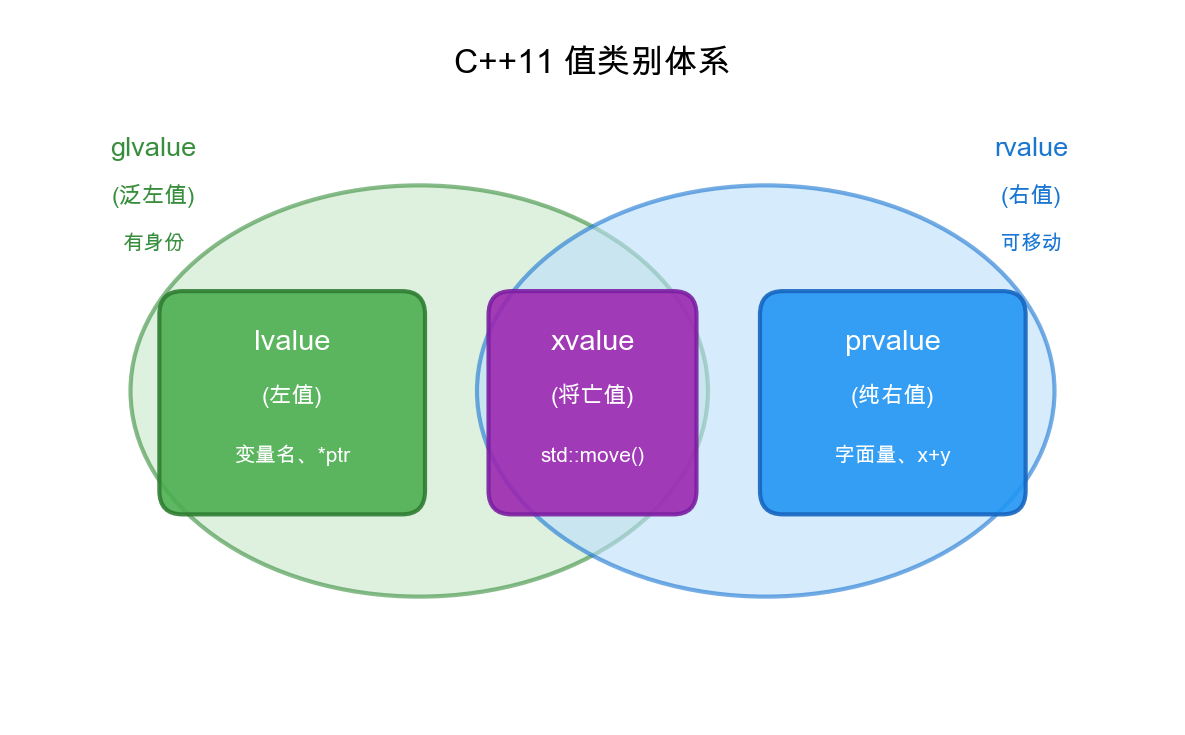
lvalue(左值)是有持久身份的表达式,可以取地址,例如变量名、解引用表达式、返回左值引用的函数调用:
1 | int x = 10; |
prvalue(纯右值)是没有身份的临时值,不能取地址,例如字面量、算术表达式、返回非引用类型的函数调用:
1 | int x = 10; |
xvalue(将亡值)是有身份但即将被移动的表达式,例如std::move(x)的结果、返回右值引用的函数调用。
这三个基本类别又组成两个复合类别:glvalue(泛左值)= lvalue + xvalue,表示”有身份”;rvalue(右值)= prvalue + xvalue,表示”可移动”。
值类别的核心意义在于:编译器通过值类别判断一个表达式是否可以被”移动”。右值表示”这个值即将消亡或已被标记为可移动”,因此可以安全地窃取其资源。
左值引用与右值引用
值类别是表达式的属性,而引用是绑定表达式的语法机制。C++11引入右值引用,正是为了让函数能够区分传入的是左值还是右值,从而采取不同的处理策略。
C++98只有一种引用——左值引用(T&),它只能绑定到左值。C++11新增了右值引用(T&&),它可以绑定到右值。
1 | int x = 10; |
const左值引用是一个例外,它可以绑定到右值。这是C++98的设计决策:为了让函数能够接受临时对象作为参数(避免不必要的拷贝),需要有一种引用能绑定到右值。普通左值引用T&做不到这一点,而临时对象本身是只读的(即将销毁,修改无意义),const引用承诺不修改对象,语义上恰好匹配,因此规定const左值引用可以绑定右值:
1 | void process(std::string& s); |
C++11引入右值引用后,两者并非替代关系,而是分工合作:
| 引用类型 | 能绑定的值 | 语义目的 |
|---|---|---|
T& |
左值 | 修改原对象 |
const T& |
左值、右值 | 只读访问,不关心来源 |
T&& |
右值 | 窃取资源,移动语义 |
当只需要读取数据、不关心对象是左值还是右值时,const T&仍是最佳选择。而T&&专门用于”需要窃取资源”的场景。实践中两者经常配合使用:
1 | class MyClass { |
这样调用者传左值时拷贝,传右值时移动,兼顾通用性和性能。这种重载模式之所以有效,是因为编译器能根据参数的值类别选择匹配的函数:传入临时对象或std::move标记的对象时匹配右值引用版本,传入普通变量时匹配const引用版本。
理解右值引用时有一个容易混淆的点:右值引用变量本身是左值。rref虽然是int&&类型,但作为一个有名字的变量,它是左值:
1 | int&& rref = 10; |
这意味着右值引用变量不能直接传递给另一个接受右值引用的函数,需要再次使用std::move:
1 | void consume(std::string&& s); |
移动构造与移动赋值
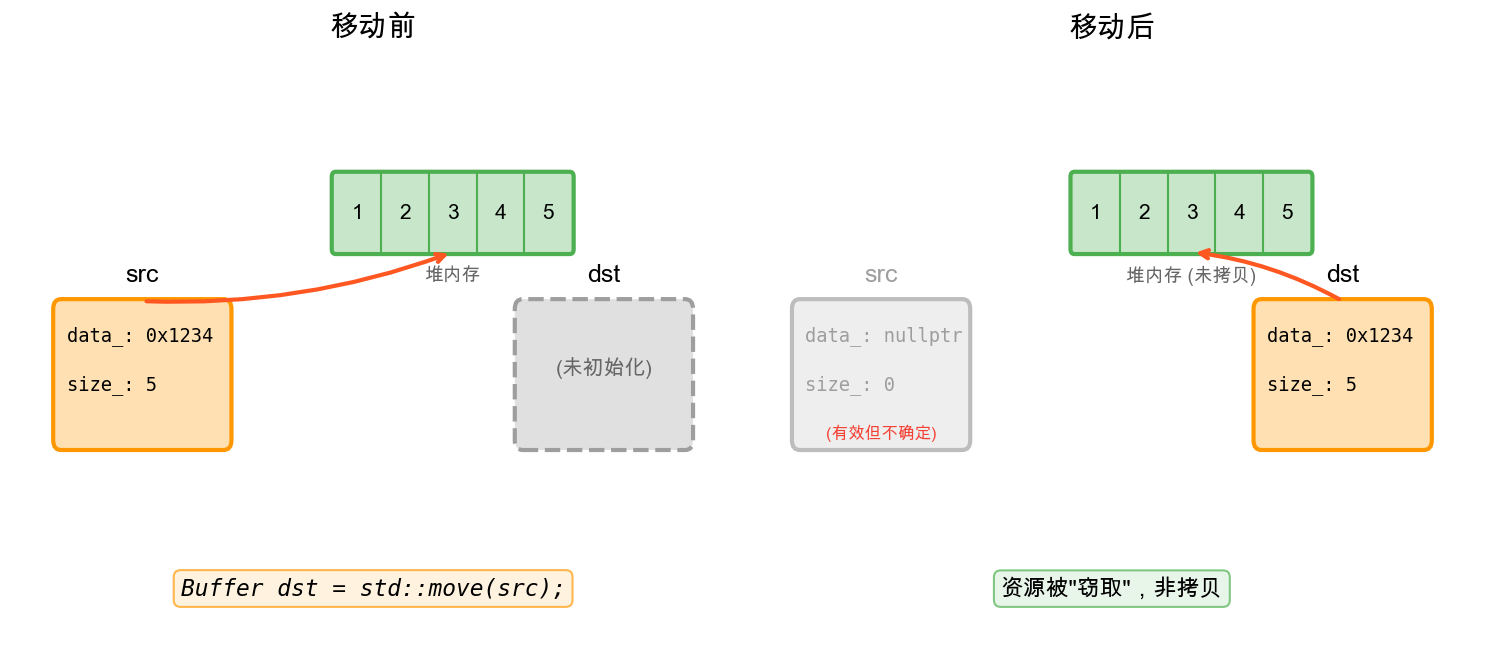
有了右值引用作为语法基础,就可以为类定义移动构造函数和移动赋值运算符。它们接受右值引用参数,通过”窃取”源对象的资源来初始化或赋值,而非深拷贝。
以一个简单的动态数组类为例:
1 | class Buffer { |
移动操作的关键点有三个:
参数类型是右值引用(
Buffer&&),只有传入右值时才会匹配。窃取资源后必须将源对象置于”有效但不确定”的状态,通常是将指针置空。所谓”有效但不确定”,是指标准库保证被移动对象可以安全析构和重新赋值,但不保证其内部状态(如
string的内容、vector的元素)。这确保源对象析构时不会释放已被窃取的资源。移动操作应标记为
noexcept。标准库容器在扩容时,只有当元素的移动构造函数是noexcept时才会使用移动而非拷贝,否则为保证异常安全会退回到拷贝。这是因为扩容需要把所有元素搬到新内存,如果搬到一半抛异常,已移动的元素资源被窃取,无法恢复原状态;而拷贝失败时原对象完好,可以安全回滚。普通的单次赋值(如vec[0] = std::move(obj))不受此限制,因为单次操作失败不涉及批量状态回滚。
实际使用时,编译器会根据参数的值类别自动选择合适的版本:
1 | Buffer a(100); |
std::move
移动构造和移动赋值只在参数是右值时被调用,但有时我们明确知道某个左值对象不再需要了,希望主动触发移动。std::move正是为此而设计。
std::move的名字具有误导性——它并不移动任何东西,只是将左值无条件转换为右值。
1 | template<typename T> |
本质上,std::move就是一个类型转换。它告诉编译器:”我不再需要这个对象的值了,可以把它当作右值来处理。”真正的移动发生在后续的移动构造或移动赋值中。
1 | std::string s1 = "hello"; |
使用std::move后,源对象处于”有效但不确定”的状态。标准库保证被移动对象可以安全地析构和重新赋值,但不保证其具体内容。实践中应避免在移动后继续使用源对象的值:
1 | std::vector<int> v1 = {1, 2, 3}; |
何时使用std::move?当你确定一个对象不再需要其当前值,且希望将其资源转移给另一个对象时。典型场景包括:
1 | // 1. 将成员对象移出 |
注意不要对返回局部对象的场景使用std::move,这会阻止RVO,反而降低性能。
完美转发
前面介绍的std::move用于主动放弃对象的所有权,而在泛型编程中还有另一个问题:如何在转发参数时保持其原本的值类别?如果调用者传入右值,转发时却变成了左值,就会意外触发拷贝而非移动。这就是”完美转发”要解决的问题。
考虑一个简单的包装函数:
1 | template<typename T, typename Arg> |
即使调用者传入右值std::move(s),在create内部,arg作为具名参数是左值,传递时会匹配拷贝构造而非移动构造。我们希望的是:调用者传左值就按左值转发,传右值就按右值转发。这就是”完美转发”要解决的问题。
引用折叠
C++11引入了引用折叠规则来解决这个问题。当出现”引用的引用”时,按以下规则折叠:
| 原始类型 | 加上 & | 加上 && |
|---|---|---|
| T& | T& | T& |
| T&& | T& | T&& |
简言之:只要有一个左值引用,结果就是左值引用;只有两个右值引用叠加才得到右值引用。
举个例子,假设有类型别名using T = int&,那么T&&就是int& &&,根据折叠规则得到int&。
这个规则是万能引用能够同时接受左值和右值的底层原理:当模板参数根据实参推导出不同类型时,T&&会折叠成对应的左值引用或右值引用。
万能引用
当模板参数形如T&&时,如果T需要推导,则这个T&&不是普通的右值引用,而是万能引用(也称转发引用)。它可以绑定到左值或右值:
“T需要推导”指
T的类型由编译器根据实参自动推断。如果T已经确定(如类模板实例化Wrapper<int>中的成员函数参数T&&,或显式指定foo<int>(10)),则T&&就是普通右值引用。
1 | template<typename T> |
当传入左值时,T被推导为左值引用类型(如int&),T&&折叠为int&;当传入右值时,T被推导为非引用类型(如int),T&&就是int&&。
std::forward
万能引用能够接收任意值类别的参数,但在函数体内,arg作为具名变量总是左值。要将其以原本的值类别转发出去,需要使用std::forward:
1 | template<typename T> |
std::forward<T>(arg)的行为是:
- 若
T是左值引用类型,返回左值引用 - 若
T是非引用类型,返回右值引用
这样就能保持参数原本的值类别,实现”完美转发”。完美转发的典型应用是工厂函数和包装函数:
1 | template<typename T, typename... Args> |
make_unique在堆上创建对象并返回管理它的unique_ptr,它将参数完美转发给T的构造函数。上例中,p1传入C字符串,匹配std::string的const char*构造函数(普通构造);p2传入左值,匹配拷贝构造;p3传入右值,匹配移动构造。
返回值优化
移动语义大幅降低了临时对象的开销,但编译器其实还有更激进的优化手段——直接省略临时对象的构造。返回值优化(Return Value Optimization,RVO)允许在返回局部对象时跳过拷贝或移动构造,直接在调用方的内存位置构造对象。理解RVO与移动语义的关系,有助于写出更高效的代码。
1 | std::string createString() { |
按语义分析,上述代码涉及两次构造:函数内构造临时对象,然后移动构造返回值;调用方再用返回值移动构造s。但实际上,编译器会直接在s的内存位置构造字符串,整个过程只有一次构造,没有任何拷贝或移动。
RVO有两种形式:
NRVO(Named Return Value Optimization)针对具名局部变量:
1 | std::vector<int> createVector() { |
RVO针对匿名临时对象:
1 | std::string getMessage() { |
C++17之前,RVO是可选优化,编译器可以不做。C++17起,对于prvalue的情况(如return std::string("hello")),强制要求省略拷贝/移动,这被称为”强制拷贝省略”(Mandatory Copy Elision)。NRVO仍然是可选的,但主流编译器在开启优化时几乎都会执行。
尽管编译器对RVO的支持已经相当成熟,但某些代码模式会阻止优化生效。典型的失效场景包括:
1 | std::string getString(bool flag) { |
当存在多个可能的返回路径,或返回的是参数而非局部变量时,编译器无法确定在哪个对象的位置直接构造,NRVO失效。此时会退回到移动构造(如果可用)或拷贝构造。
一个常见误区是在返回语句中使用std::move:
1 | std::string createString() { |
显式std::move会将返回表达式从左值变为右值,导致返回类型从”具名局部变量”变为”右值表达式”。编译器对具名局部变量有专门的NRVO优化路径,而std::move后变成了普通的移动构造,反而阻止了优化。
实际上,编译器处理函数返回时有明确的优先级:首先尝试RVO/NRVO直接省略构造;若不可行,对局部对象隐式应用移动语义;最后才是拷贝构造。因此返回局部对象时,直接return obj;是最佳写法——既给编译器留出NRVO的优化空间,又能在NRVO失败时自动获得移动语义的兜底。
移动语义的价值
移动语义带来的性能收益是显著的。以std::vector为例,当容量不足需要扩容时,旧的做法是将所有元素逐个拷贝到新内存;有了移动语义,可以直接移动元素,对于管理动态资源的类型(如std::string、std::vector),性能提升可达数量级。
1 | std::vector<std::string> v; |
移动语义也改变了资源管理的设计思路。移动专有型(move-only)类型如std::unique_ptr、std::thread只能移动不能拷贝,这从类型系统上保证了资源的唯一所有权:
1 | std::unique_ptr<int> p1 = std::make_unique<int>(42); |
实践建议
为自定义类实现移动语义时,遵循以下原则:
如果类管理动态资源(如指针、文件句柄),应实现移动构造和移动赋值。
移动操作应标记为
noexcept,除非确实可能抛出异常。被移动对象应置于有效但不确定的状态,通常是将资源指针置空。
遵循”五法则”:如果定义了析构函数、拷贝构造、拷贝赋值、移动构造、移动赋值中的任何一个,通常应该定义全部五个。
对于不管理资源的简单类,编译器生成的默认移动操作通常就足够了,无需显式声明。
移动语义是C++11最重要的特性之一,它在不改变代码语义的前提下显著提升了性能。理解值类别、右值引用、std::move和完美转发这几个核心概念,是掌握现代C++的关键。