C++内存布局与生命周期
C++程序运行时,内存被划分为几个不同的区域,每个区域有不同的分配方式、生命周期和性能特点。理解这些区域的差异,是掌握C++内存管理的基础。
内存区域概览
程序中的数据有不同的特点:指令不可修改、全局数据贯穿始终、局部变量随调随销、动态数据大小不定。将它们混在一起管理既不安全也不高效,因此操作系统将内存划分为不同区域,针对各自特点采用最合适的管理策略。
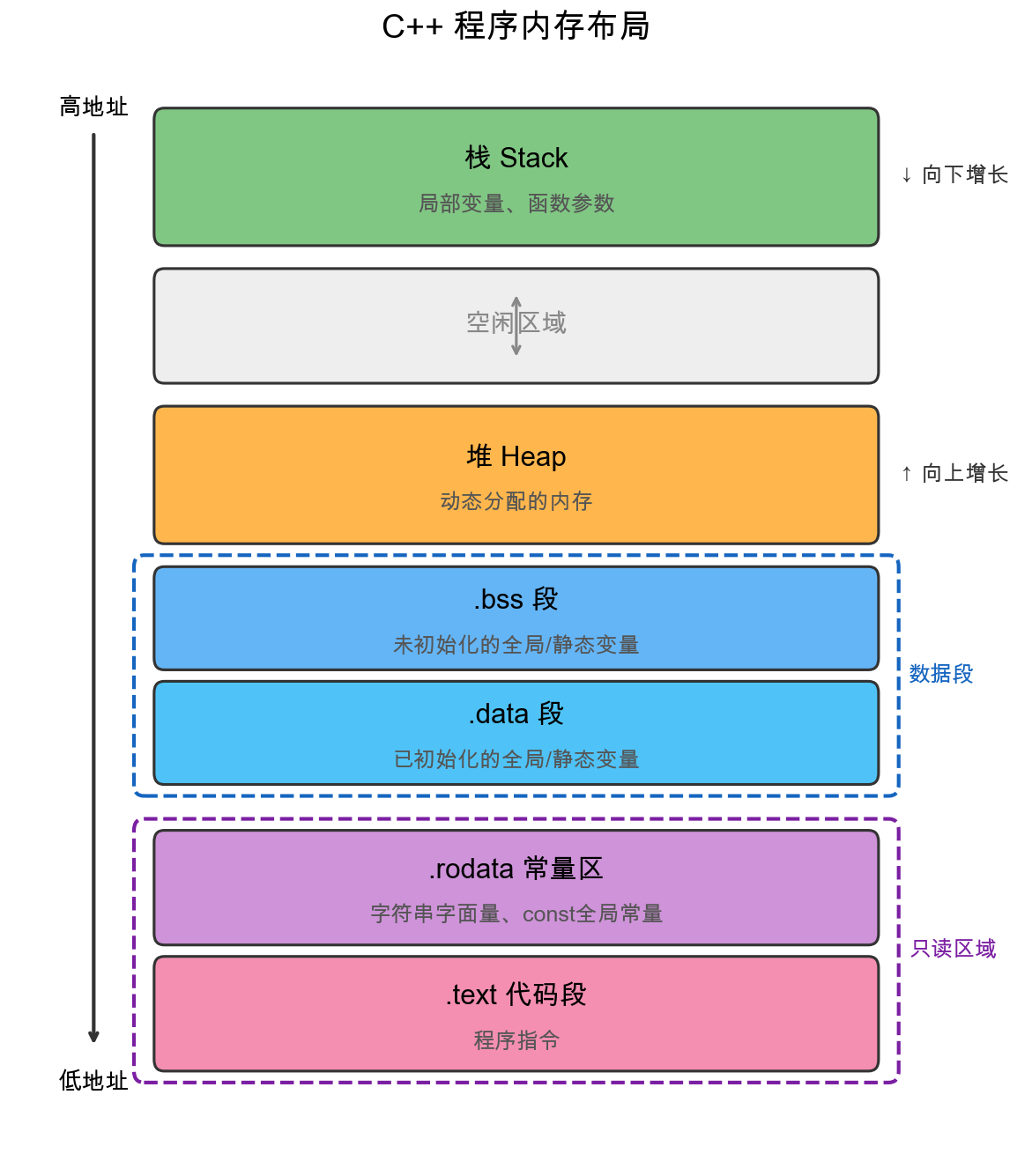
如图所示,从低地址到高地址依次为:
代码段(.text)存放编译后的机器指令,只读且在程序运行期间保持不变,防止程序意外修改自身逻辑。
常量区(.rodata)存放只读数据,包括字符串字面量和const全局常量。编译器可能将相同的字符串字面量合并为一份,尝试修改常量区内容会导致程序崩溃。
数据段存放全局变量和静态变量,生命周期与程序一致。其中.data段存放已初始化的变量,.bss段存放未初始化的变量。
堆是一块较大的内存池,通过new/delete手动管理,向上增长。堆分配的对象不会随函数返回而销毁,必须显式释放。分配速度较慢(需要内存分配算法),频繁分配/释放可能产生碎片。
栈由编译器自动管理,向下增长。函数调用时栈指针下移分配空间,返回时回退释放,分配速度极快。但栈空间有限(通常1-8MB),且不会自动清零。
各区域特点汇总:
| 区域 | 存储内容 | 分配方式 | 生命周期 |
|---|---|---|---|
| 代码段 | 程序指令 | 编译时确定 | 程序运行期间 |
| 数据段 | 全局/静态变量 | 编译时确定 | 程序运行期间 |
| 常量区 | 字符串字面量、const常量 | 编译时确定 | 程序运行期间 |
| 堆 | 动态分配的对象 | 手动分配 | 手动释放前 |
| 栈 | 局部变量、函数参数 | 自动分配 | 函数调用期间 |
从布局图还能看出一个重要细节:栈和堆相向增长——栈从高地址向下,堆从低地址向上。这种设计是为了最大化利用内存空间:编译时无法预知两者各需多少空间,让它们从两端相向增长,中间区域就能被灵活共享。
代码段
代码段(.text段)存放编译后的机器指令,是程序的”只读执行区”。编译器将源代码翻译成CPU可执行的二进制指令后,这些指令被写入可执行文件的.text段,程序加载时映射到内存中。
操作系统将代码段设置为只读且可执行,这种权限设置出于安全考虑:只读防止程序意外或恶意修改自身逻辑,可执行则允许CPU从这块内存取指令运行。现代操作系统还实施W^X(Write XOR Execute)策略——内存页要么可写要么可执行,但不能同时具备两种权限,以防御代码注入攻击。
代码段的内容在编译时就已完全确定,运行期间保持不变。函数的机器码、虚函数表(vtable)等都存放在这里。
虚函数表是实现运行时多态的关键数据结构——每个含虚函数的类都有一张表,存储该类各虚函数的地址;对象通过内部的vptr指针找到所属类的vtable,从而在运行时调用正确的函数版本。
当调用一个普通函数时,CPU的程序计数器(PC)跳转到该函数在代码段中的地址开始执行:
1 | void foo() { |
函数指针的值实际上就是函数在代码段中的地址。通过函数指针可以间接调用函数,这也是回调机制和多态实现的基础:
1 | void greet() { |
由于代码段只读,试图修改函数指令会触发段错误。这种保护机制确保了程序逻辑的完整性,也是操作系统安全模型的重要组成部分。
常量区
除了可执行指令,程序中还有一类数据同样不应被修改——字符串字面量和const全局常量。它们被存放在常量区(.rodata段),与代码段一样享有只读保护。
字符串字面量
所谓字面量(Literal),是指在代码中直接书写的固定值,如"hello"是字符串字面量、42是整数字面量、3.14是浮点数字面量。字符串字面量之所以存储在常量区,是因为它们在编译时就已确定,且通常不应被修改——编译器会把这些字符串写入可执行文件的只读数据段,程序运行时直接映射到内存。
1 | const char* str1 = "hello"; // "hello"存储在常量区,str1是指向它的指针 |
字符串字面量存储在只读数据段,操作系统将这块内存设置为只读权限。当程序试图修改字符串字面量时,CPU会触发保护异常,操作系统随即向进程发送段错误信号(SIGSEGV),终止程序运行:
1 | char* p = "hello"; // 不推荐:将const char*赋给char* |
如果需要可修改的字符串,应该使用字符数组:
1 | char str[] = "hello"; // 字符串内容被复制到栈上 |
两种写法的区别在于初始化语义不同。
char* p = "hello"中,"hello"的类型是const char[6],初始化指针时发生数组退化(array decay)——数组自动转换为指向首元素的const char*,p只是指向常量区那块内存,并没有复制任何内容。而char str[] = "hello"中,str是一个字符数组,编译器会把字面量的内容逐字符复制到栈上新分配的空间,str拥有独立的内存副本。简言之:指针初始化是”指向”,数组初始化是”复制”。数组退化的设计源于C语言追求简洁高效的理念——传递数组时只传地址而非整个数组,既节省栈空间又避免复制开销。
const全局常量
需要注意const全局常量与const局部变量的区别。const全局常量存储在常量区,而const局部变量存储在栈上——const关键字只是让编译器在编译期阻止修改,并不改变变量的存储位置:
1 | const int MAX_SIZE = 100; // 全局常量,存储在常量区 |
数据段
常量区存放的是不可修改的只读数据,而程序中还有一类数据虽然同样在编译时确定、生命周期贯穿始终,却需要在运行时被修改——这就是全局变量和静态变量,它们被存放在数据段。 它们在程序启动时分配,程序结束时释放,有三种具体形式:
| 类型 | 生命周期 | 可见性 | 默认初始化 |
|---|---|---|---|
| 全局变量 | 程序运行期间 | 所有文件(extern) | 0 |
| 静态全局变量 | 程序运行期间 | 仅当前文件 | 0 |
| 静态局部变量 | 程序运行期间 | 仅当前函数 | 0 |
三者的生命周期和存储位置相同,区别仅在于可见性:全局变量默认可被其他文件访问,static关键字则将可见性限制在当前文件或函数内。
根据是否显式初始化,这些变量被分配到不同的子段。未初始化的变量放在.bss段,程序加载时由操作系统清零;已初始化的变量放在.data段,初始值被编入可执行文件:
1 | int a; // 全局变量,.bss段,自动初始化为0 |
.bss(Block Started by Symbol)这个术语源自1950年代IBM 704的汇编语言。将未初始化变量单独存放的设计节省的是磁盘空间而非运行时内存。以
int data[2621440](10MB未初始化数组)为例:如果把10MB的零值写入可执行文件,文件体积就要增加10MB;而.bss段只在文件中记录”需要10MB”这个元信息(几个字节),程序加载时由操作系统分配内存并清零。两者运行时占用的内存相同,但.bss让可执行文件更小——这在早期存储昂贵的年代尤为重要,对于嵌入式系统或需要网络传输的程序,减小文件体积至今仍有意义。
全局变量
全局变量的初始化都在main()执行前完成,销毁则在main()返回后进行。对于基本类型,初始化在程序加载时由操作系统完成;对于类类型,则需要在运行时调用构造函数:
1 | int global_int = 42; // 加载时初始化,值直接从.data段读取 |
静态局部变量
静态局部变量同样位于数据段,生命周期贯穿整个程序运行期间,但其可见性受限于定义它的函数作用域。与全局变量不同,静态局部变量在首次执行到定义语句时才初始化:
1 | void counter() { |
上述代码中,count只会初始化一次,多次调用counter(),count的值会累加。从C++11开始,静态局部变量的初始化是线程安全的,编译器会自动加锁保护。这一特性使其成为实现单例模式的最佳方式:
1 | class Singleton { |
首次调用getInstance()时,instance被构造;之后的调用直接返回同一个对象。由于是静态变量,程序结束时自动析构,无需手动管理。
栈
数据段中的变量生命周期与程序一致,但程序运行时还需要处理大量临时数据——函数参数、局部变量、返回地址等。这些数据随函数调用而生、随函数返回而灭,如果也放在数据段会造成空间浪费。栈正是为此设计的:它在函数调用时分配空间,返回时自动回收,分配速度极快,只需移动栈指针即可。
1 | void foo() { |
每次函数调用都会在栈上创建一块独立的工作区域,称为栈帧(Stack Frame)。栈帧存储该函数的参数、返回地址、局部变量等信息,函数返回时整个栈帧被销毁。多层函数调用形成的栈帧依次堆叠,构成调用栈(Call Stack)。
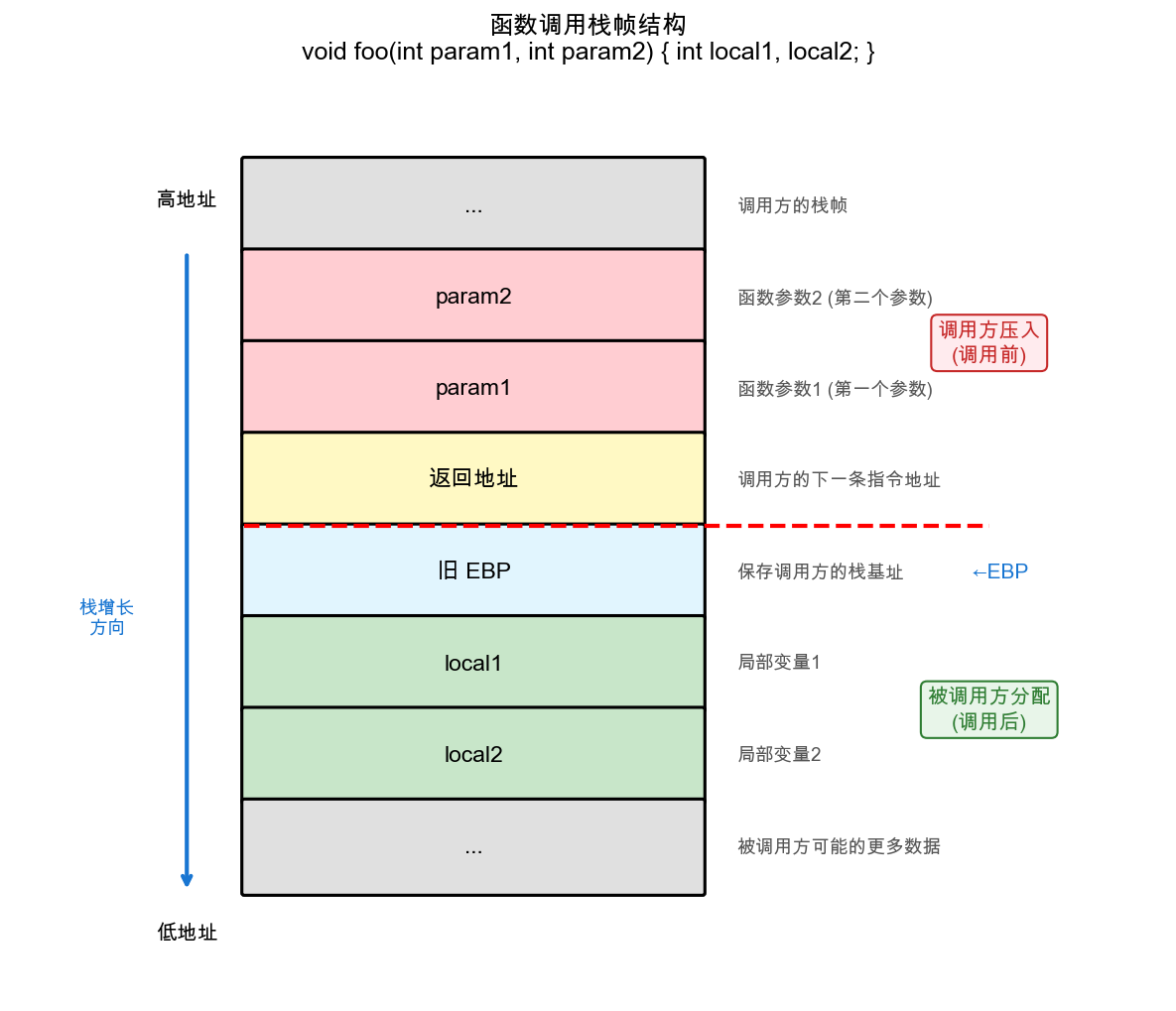
如图所示,当main()调用foo(param1, param2)时,调用方先将参数压栈,然后压入返回地址。进入foo()后,先保存旧的栈基址(EBP),再为局部变量分配空间。返回地址是栈帧的分界线:其上是调用方准备的数据(参数),其下是被调用方的工作区域(局部变量)。
EBP(Extended Base Pointer,栈基址指针)是CPU用于定位栈帧的寄存器。函数入口时,先将调用方的EBP压栈保存,然后将当前栈指针的值赋给EBP——此时EBP就指向刚保存的”旧EBP”那个位置,作为当前栈帧的基准点。通过EBP加偏移访问参数(EBP+8、EBP+12…),减偏移访问局部变量(EBP-4、EBP-8…)。函数返回时从栈中恢复旧EBP,使调用栈能正确回溯。64位系统中对应的寄存器名为RBP。
1 | void foo(int param) { // param是函数参数,调用时由调用方传入 |
需要注意的是,栈上的变量不会自动清零。与.bss段不同,栈帧在每次函数调用时都会分配,如果每次都清零性能开销太大;而且栈空间属于当前进程私有,不存在跨进程数据泄露问题。因此如果不显式初始化,局部变量的值是随机的(之前栈帧留下的数据),这是很多未初始化变量bug的来源。对于类类型的局部对象,编译器会确保在进入作用域时调用构造函数,离开时调用析构函数:
1 | void test() { |
堆
栈虽然高效,但有两个根本限制:大小必须在编译时确定,生命周期必须遵循函数调用的嵌套规则。当需要运行时才能确定大小的数组、需要在函数返回后继续存活的对象,或者需要超过栈容量的大块内存时,就必须使用堆。
手动内存管理
堆是一块由程序员手动管理的内存区域。使用new分配内存,delete释放内存,堆上的对象不会随函数返回而销毁,必须显式释放,否则会造成内存泄漏:
1 | void heap_example() { |
new和delete必须配对使用,new[]和delete[]也必须配对,混用会导致未定义行为。与栈上对象不同,堆对象的生命周期完全由程序员控制——new时调用构造函数,delete时调用析构函数:
1 | void heap_lifecycle() { |
然而,手动管理堆内存容易出错:忘记释放导致内存泄漏,重复释放导致程序崩溃,释放后继续使用导致悬空指针。
智能指针
现代C++推荐使用智能指针自动管理堆对象。std::unique_ptr表示独占所有权,同一时刻只有一个指针拥有对象:
1 |
|
std::shared_ptr则表示共享所有权,内部维护一个引用计数器,每次拷贝计数加1,每次销毁计数减1,当计数归零时释放对象:
1 | void shared_example() { |
这种”计数归零才释放”的机制在正常使用时没有问题,但当两个对象通过shared_ptr互相持有对方时,就会形成循环引用——双方的引用计数都无法归零。
以父子节点为例,如果双方都用shared_ptr持有对方:
1 | struct Node { |
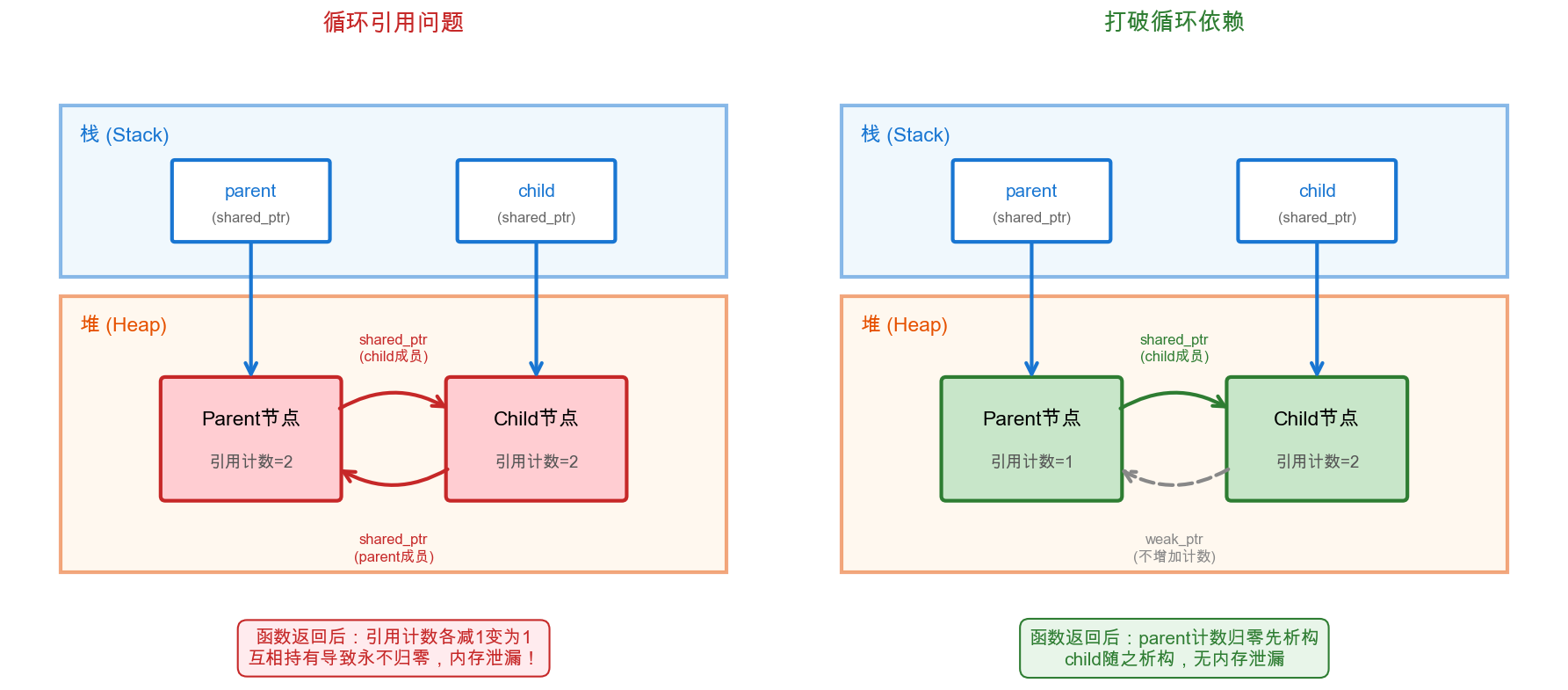
std::weak_ptr专门用于解决这个问题。它是一种”弱引用”,指向shared_ptr管理的对象但不增加引用计数。正确的做法是:父节点用shared_ptr持有子节点(控制子节点生命周期),子节点用weak_ptr指回父节点(只是引用,不控制父节点生命周期):
1 | struct Node { |
weak_ptr不保证对象存活,访问前需通过lock()获取shared_ptr:
1 | if (auto p = weak.lock()) { // 对象已释放则返回空 |
智能指针将堆对象的生命周期与栈对象绑定,利用栈的自动销毁特性来管理堆内存,这种技术称为RAII(Resource Acquisition Is Initialization,资源获取即初始化)。RAII是C++资源管理的核心思想,不仅适用于内存,也适用于文件句柄、网络连接、互斥锁等各种资源。
栈与堆的选择
了解了栈和堆的细节后,如何选择就变得清晰了。
栈的优势在于速度和安全:分配只需移动栈指针,释放随函数返回自动完成,不存在内存泄漏风险。但栈空间有限(通常1-8MB),且数据生命周期受限于函数作用域。堆则提供了更大的空间和更灵活的生命周期控制,代价是分配速度较慢、必须手动管理、频繁操作可能产生内存碎片。
| 对比项 | 栈 | 堆 |
|---|---|---|
| 分配速度 | 快(移动指针) | 慢(需要内存分配算法) |
| 空间大小 | 有限(1-8MB) | 较大(受可用内存限制) |
| 生命周期 | 自动管理 | 手动管理 |
| 碎片问题 | 无 | 频繁分配/释放可能产生碎片 |
| 访问速度 | 较快(局部性好) | 较慢(可能不连续) |
选择的一般原则是:优先使用栈,只在需要动态大小、跨作用域生存或大量内存时才使用堆。而在必须使用堆的场景中,优先选择智能指针而非裸指针,让RAII来保障内存安全。